最近编写了LLM科普的PPT,写个文章梳理下自己的思路。
大模型简介
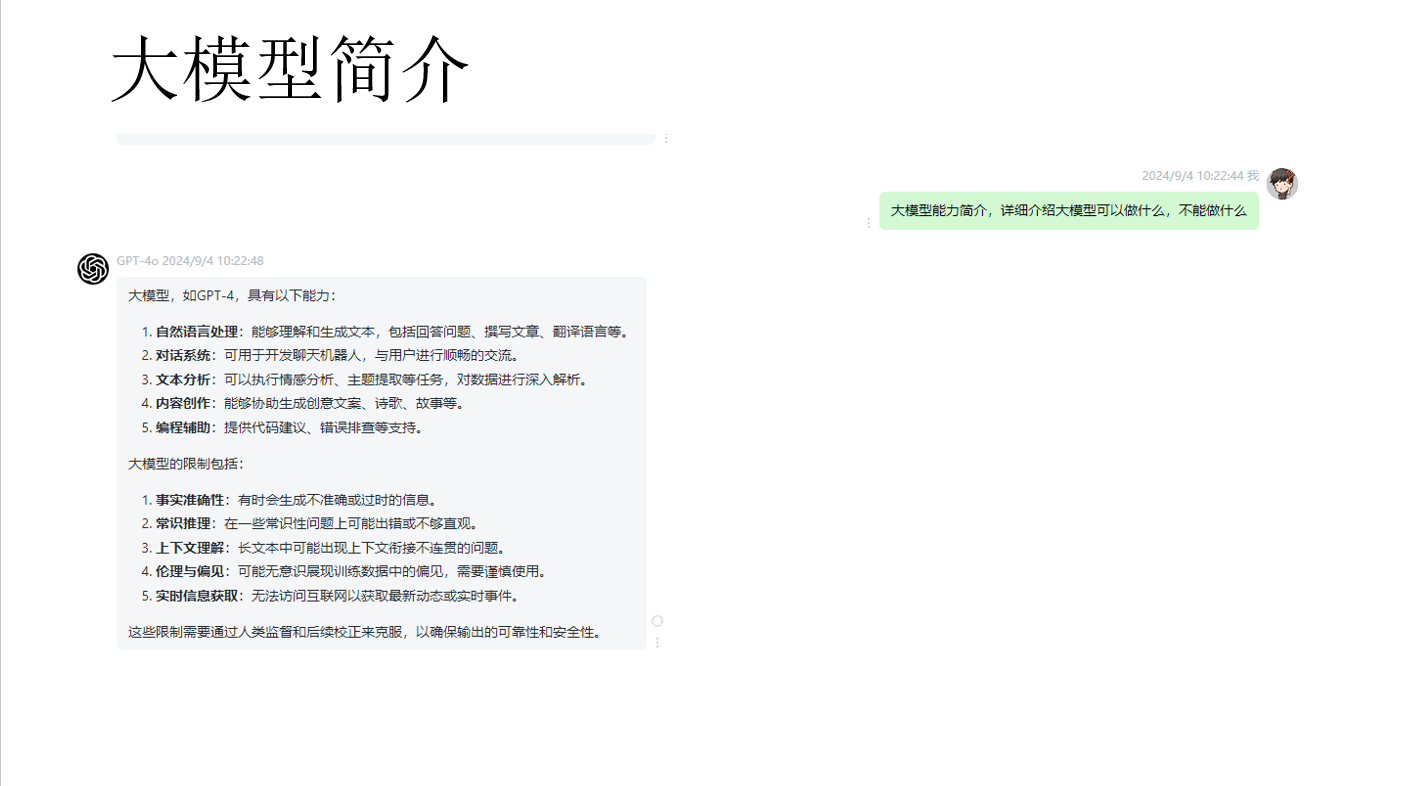
- 大模型可以用于文本类生成式任务:对话,问答,搜索等。
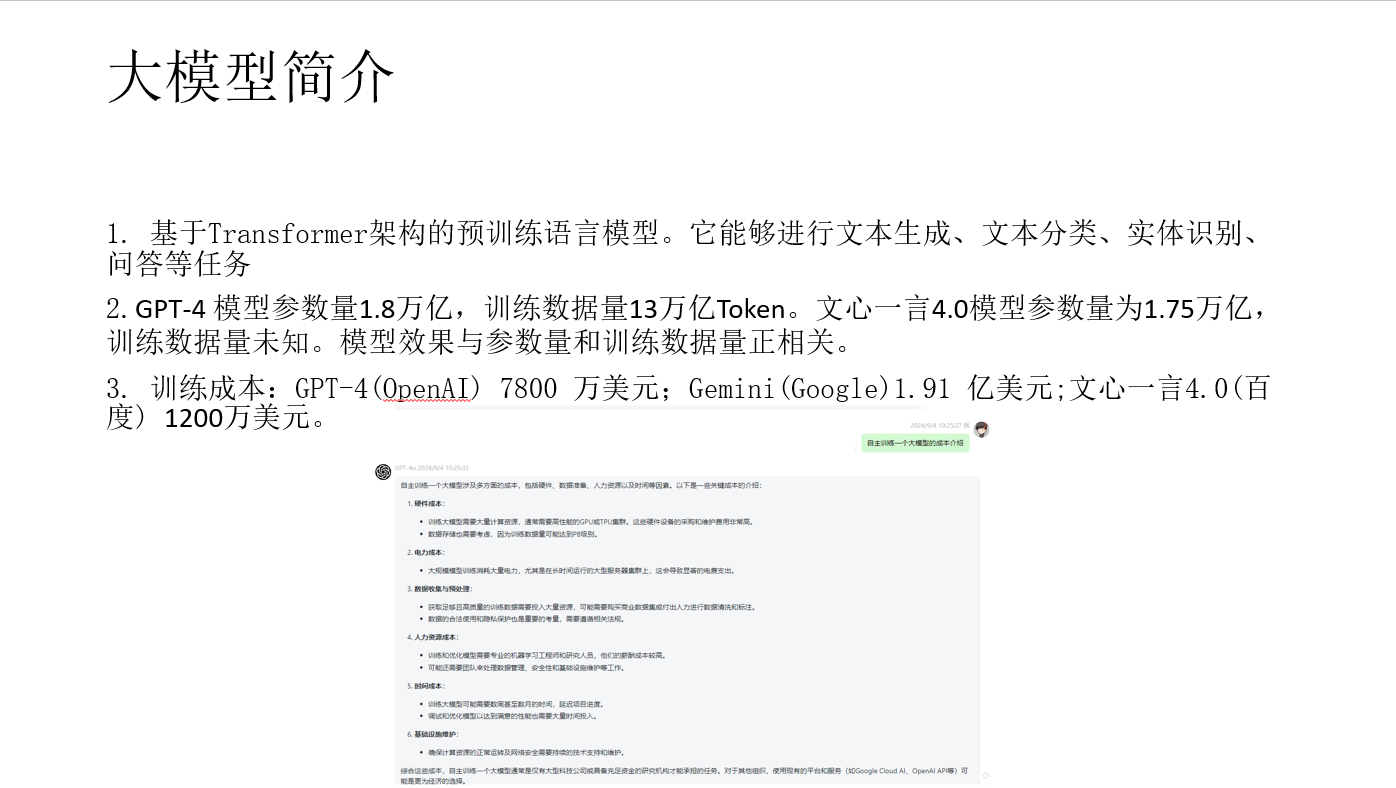
- 大模型的训练成本非常高,注定是大公司之间的游戏。
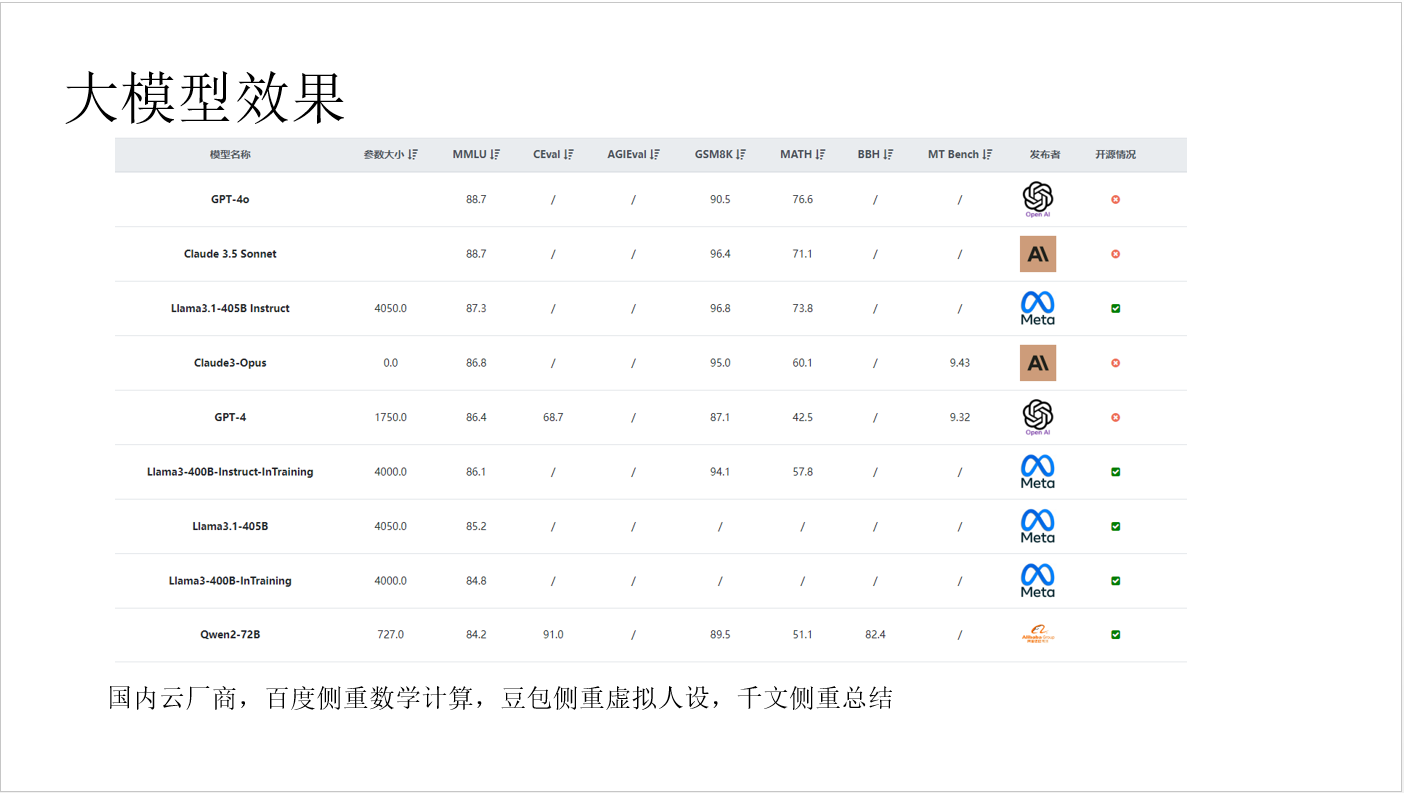
- 模型效果效果最好的是GPT-4o ,国内模型效果处于第二梯队。
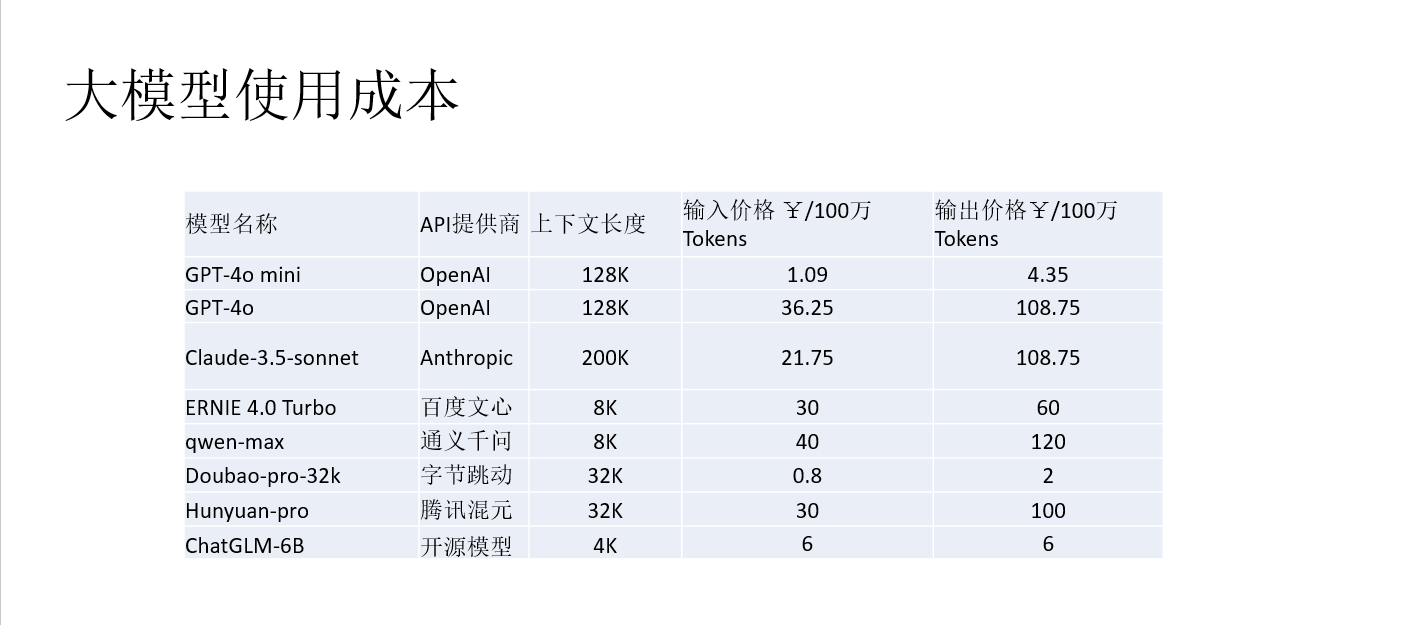
- 使用国内云厂商提供的大模型服务,成本非常低,100万token几块钱。国内服务一个汉字一个token。国外服务一个汉字约3个token。
- 大模型的使用需要提示词,在请求频繁的业务中,提示词消耗的token数可能占大头,估算成本时不要遗漏。
大模型原理
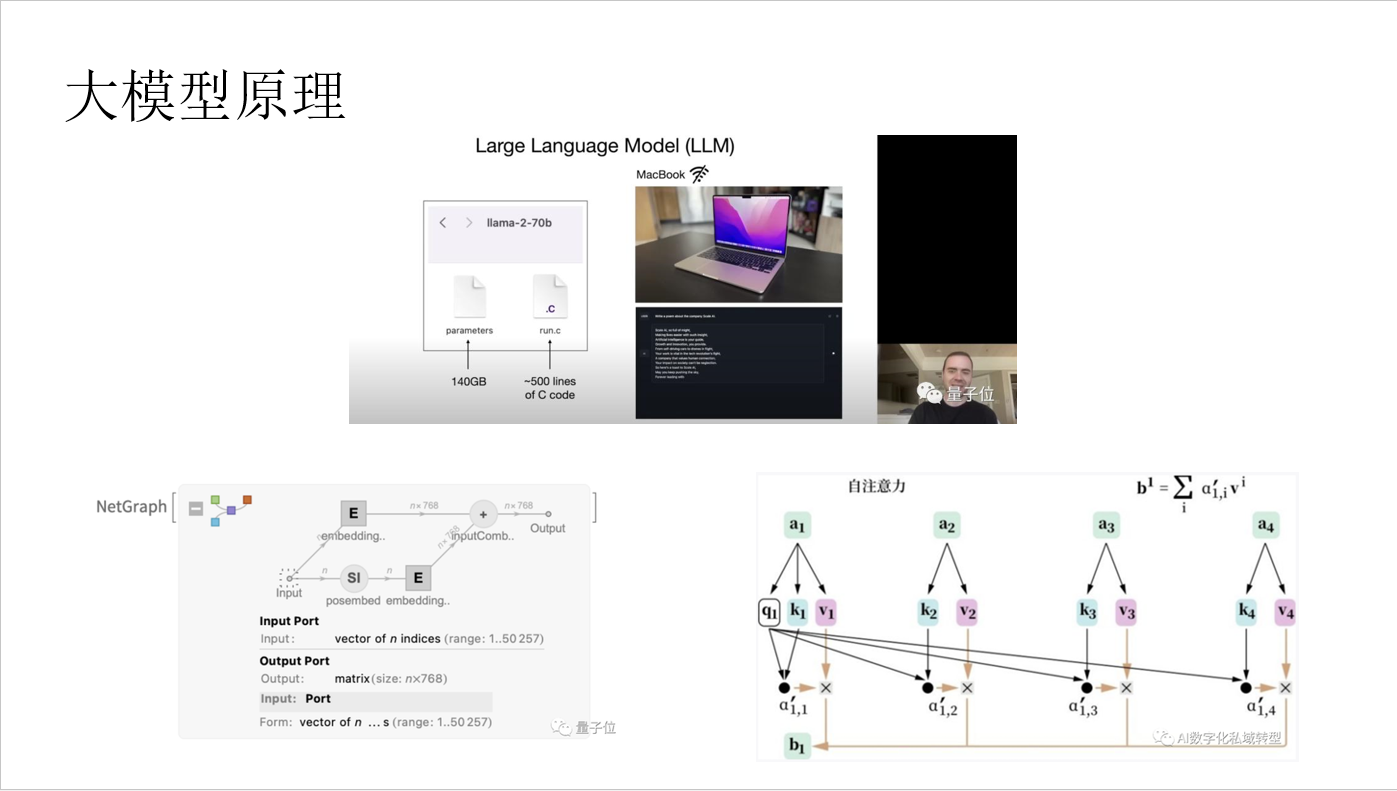
- 大模型训练需要准备海量的数据,这些数据大部分都是互联网上的内容,这些数据中包含大量通用型知识。
- 大模型本质上是通过训练的方式,将训练数据中的信息提取出来,并存储在模型中。信息提取的过程是有损的,可以理解为一种压缩。为了加快提取过程,会用到大量的GPU资源,因而训练成本非常高。
- 模型训练完成后,模型内部存储的信息就是对训练数据的理解。训练方式一致,训练数据的侧重点不同,最终模型效果也会不同,擅长的任务也会不同。
- 识别的过程,就是结合模型内部的信息来预测输入文本询问的问题。
- 模型内部有自注意力机制,预测问题不在是根据输入文本中的单个词,而是前后关联,进而提高效果。因为训练环节提取是有损的,同时预测也有准确率,所有最终给出的答案不是100%准确。
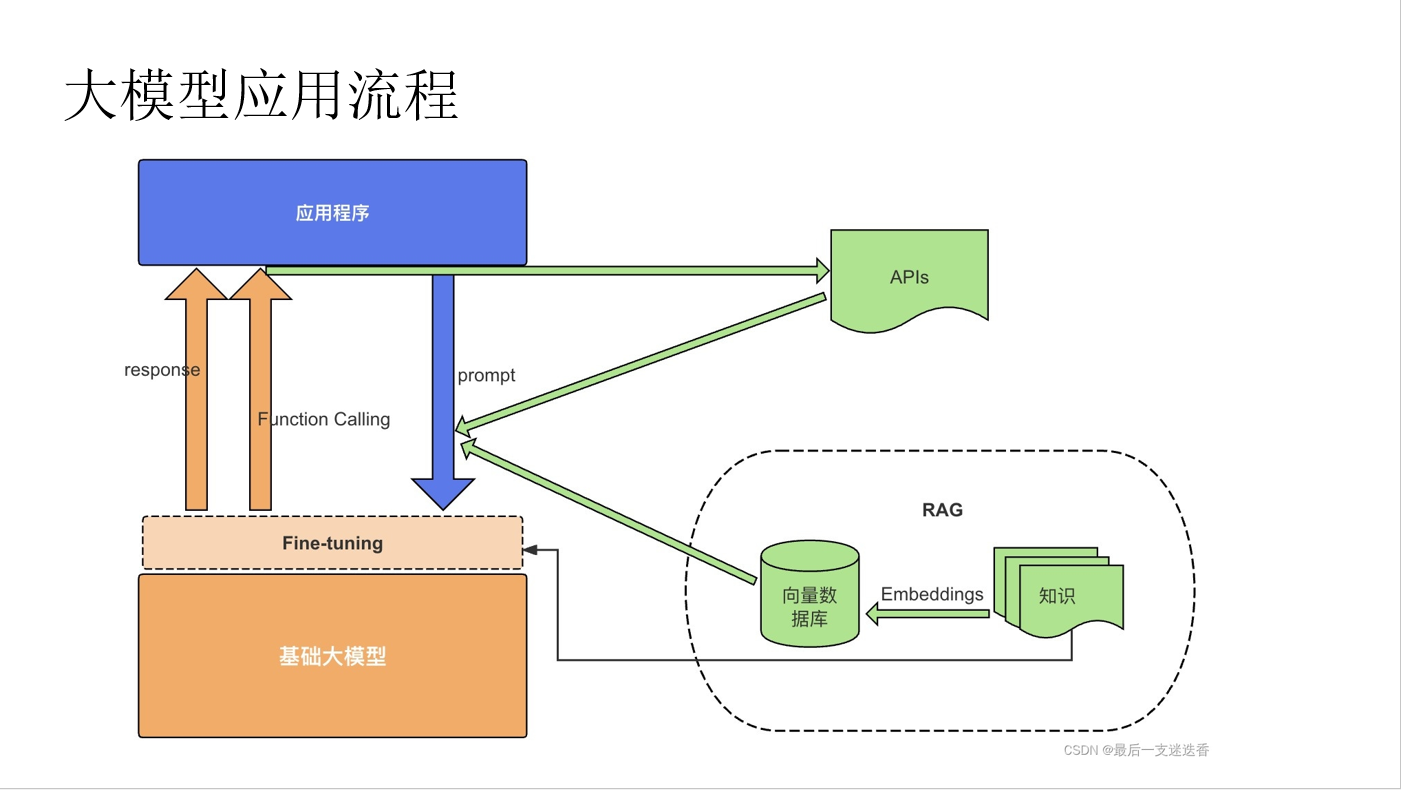
- 训练数据中不存在的信息,大模型无法回答或者只能编造。解决方案就是将相关的信息作为一个知识库,在询问时作为提示词内容一起输入模型。
- 大模型只具备文本生成能力,借助其他的系统,才能完成需要联网的任务。
大模型案例
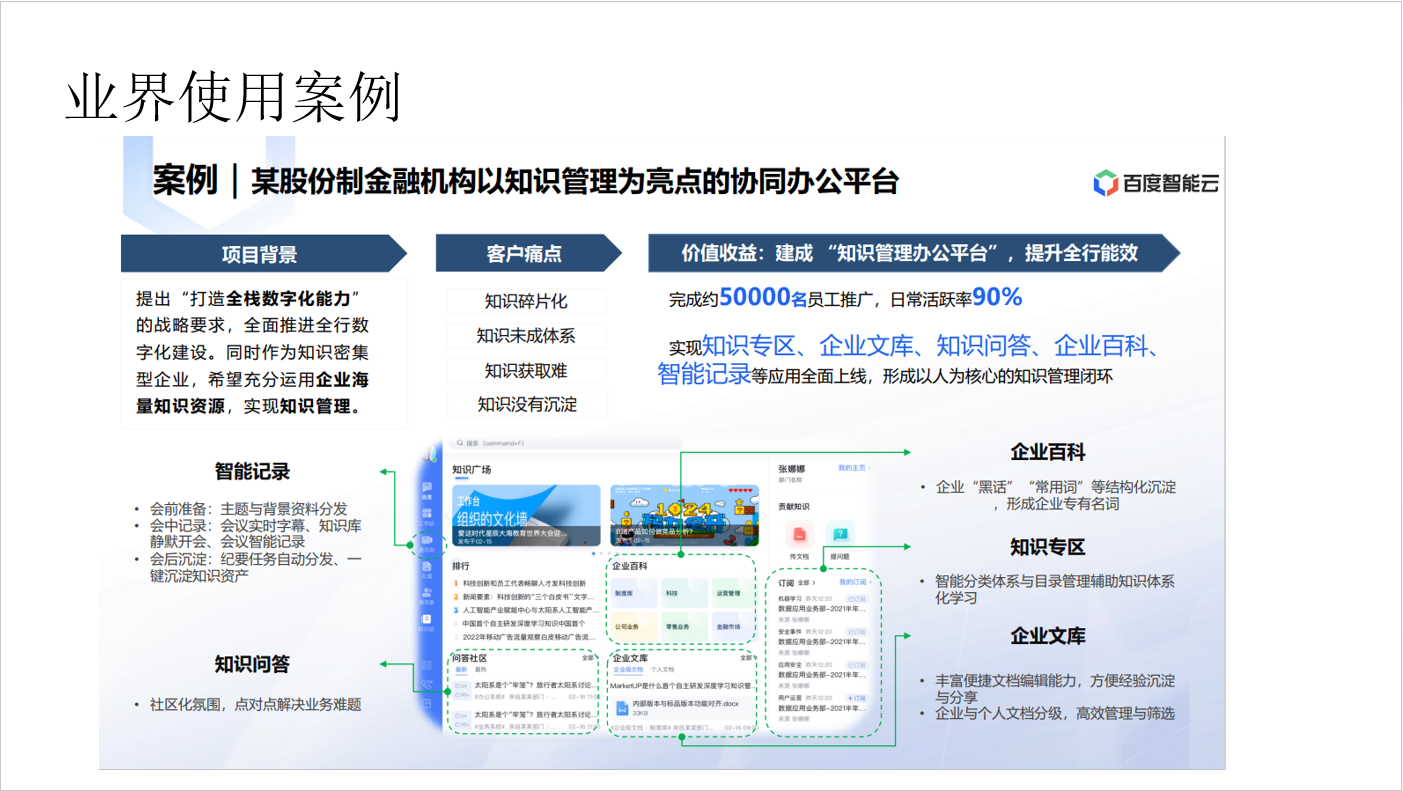
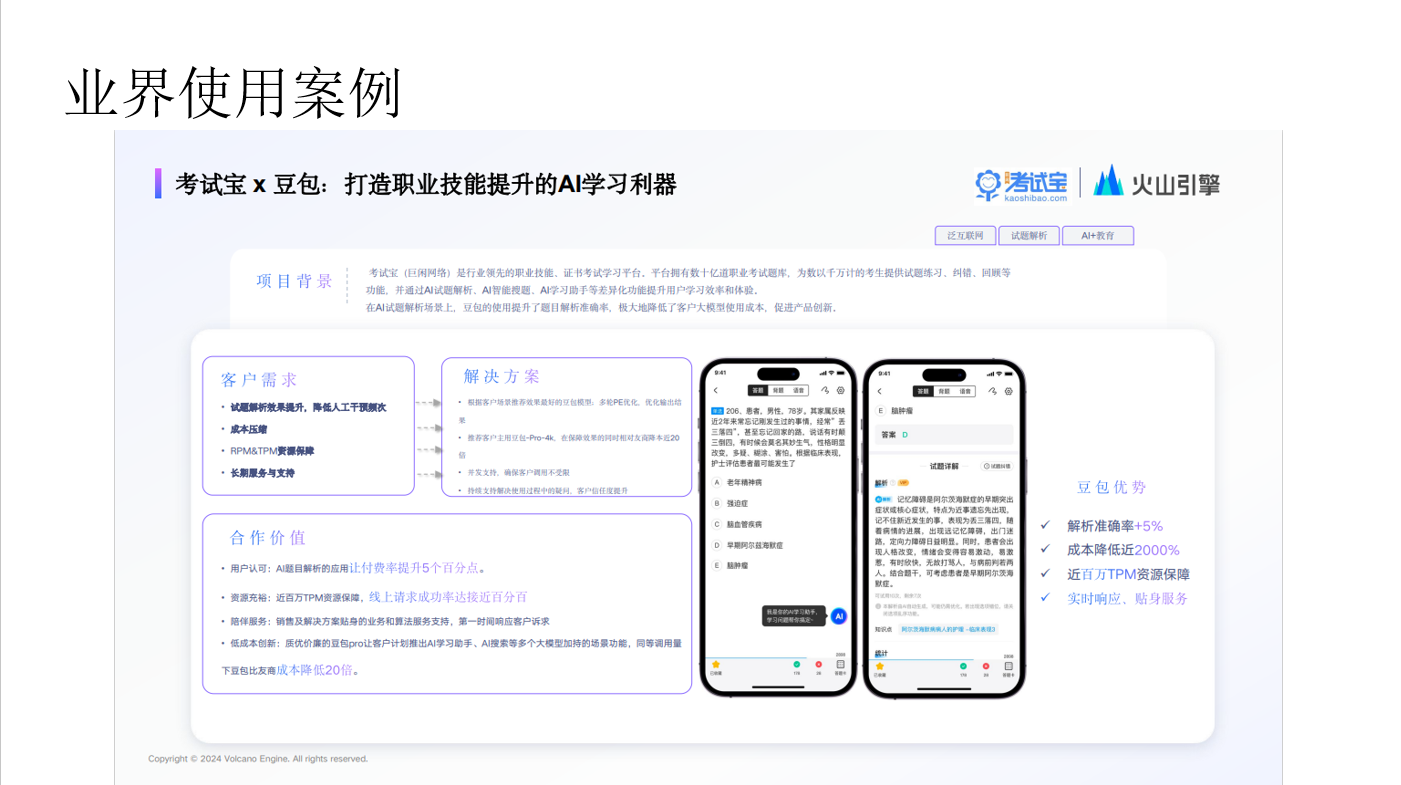
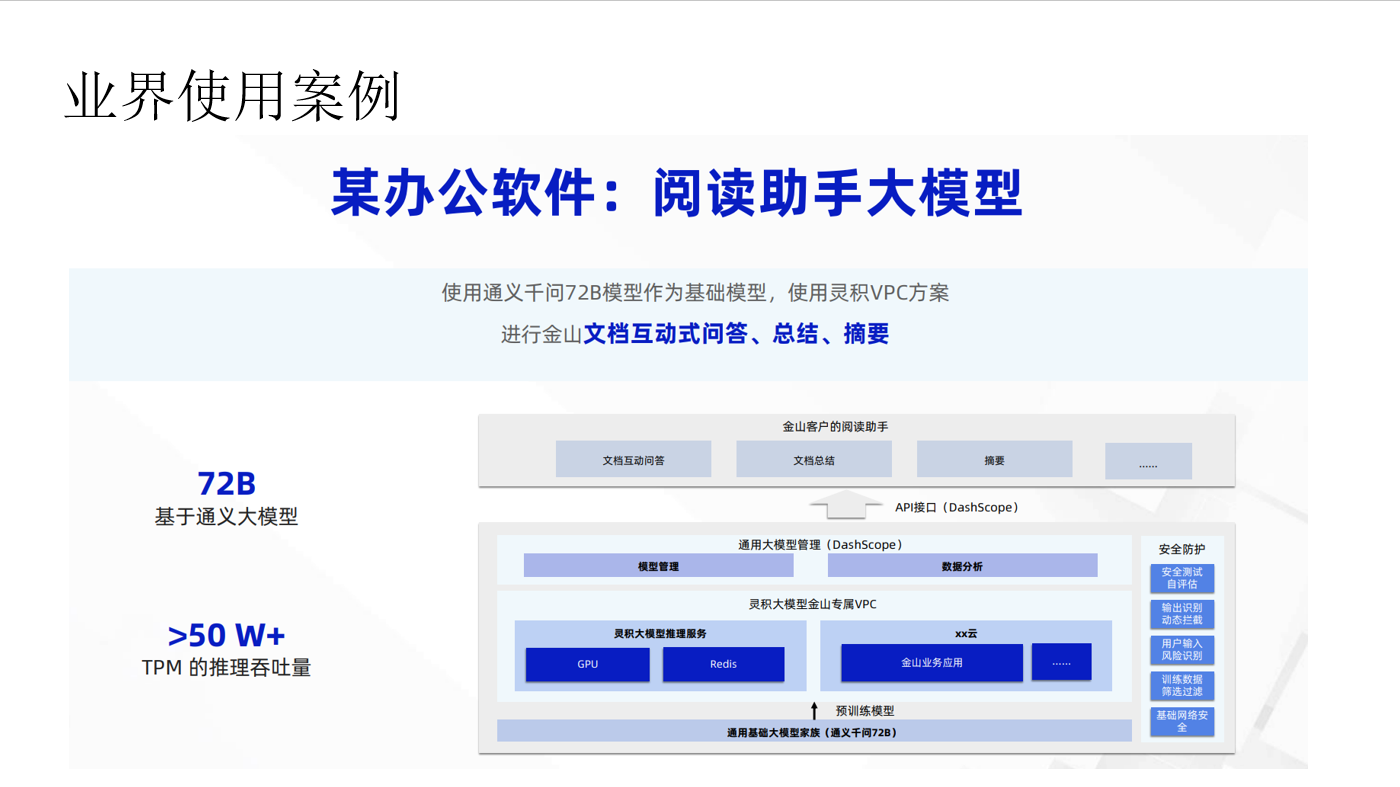
- 利用大模型的总结和提取能力,结合内部文档可以轻松搭建一个和业务紧密关联的问答系统。
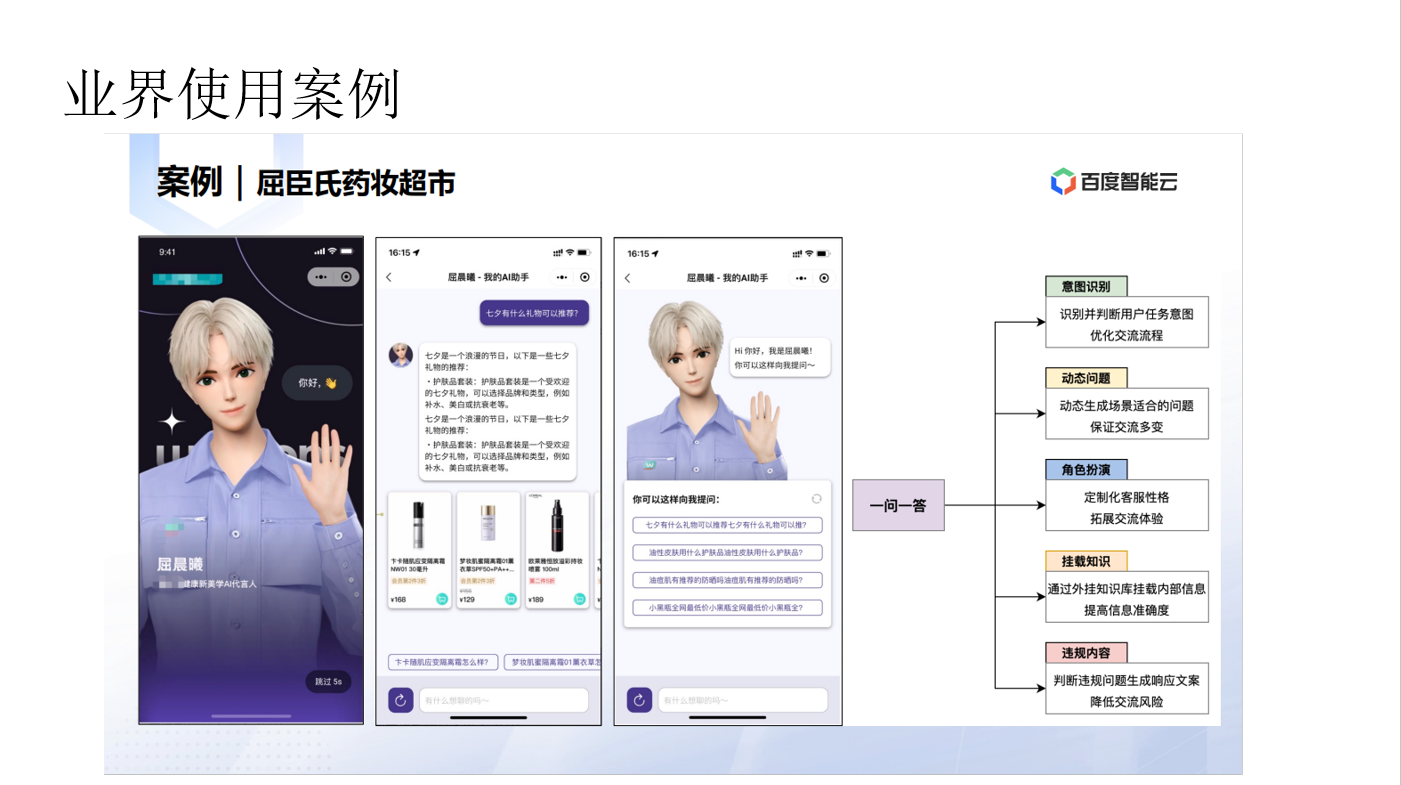
- 利用大模型的对话能力,可以提升智能客服的拟人感,同时挂载特定行业知识库,提高专业问题回答准确率。
- 利用大模型的生成能力,可以快速批量生成类似的问题。对刷题APP,使用此能力可以降低生成题目的成本。
- 利用大模型的总结和提取能力,可以对文档生成摘要,提高获取文档关键信息的效率。